Julius音声認識ソフトpart2!録音音声の認識を実行してみた
セッティングでさんざん苦労しましたが、懲りずに音声認識の第二弾に突入します。
60爺、前回は、マイクからの音声入力を行って、Juliusを動かしましたが、今度は、録音したファイルを入力にして、音声認識を行ってみます。
最初は60爺の声を録音したモノを使用しましたが、認識率が非常に悪いです。
そこで、サンプル音声をネットから拾ってきて、それをベースにして音声認識を実行しました。
その経緯を含めて、こちらも備忘録として残します。
ファイル入力の変更
録音ファイルの入力を行うには、以下の設定ファイルにある、-input mic を、-input rawfile に変えればいいだけです。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ <strong>vi raw_am-gmm.jconf</strong>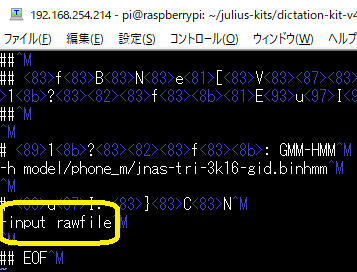
黄色枠部分が変更した箇所です。
録音データによる音声認識
録音データ指定でエラー発生
まず、音声入力をした時のコマンドをたたきます。
すると、please speakと、喋りを促された部分で、enter filenameと、録音データの指定を促されます。
ここで、録音データを指定します。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C main.jconf -C raw_am-gmm.jconf -nostrip
STAT: include config: main.jconf
STAT: include config: raw_am-gmm.jconf
STAT: jconf successfully finalized
・
・
----------------------- System Information end ----------------------- Notice for feature extraction (01),
*************************************************************
* Cepstral mean normalization for batch decoding: *
* per-utterance mean will be computed and applied. *
************************************************************* ------
### read waveform input
enter filename->/home/pi/test.wav Error: adin_file: channel num != 1 (2)
Error: adin_file: error in parsing wav header at /home/pi/test.wav
Error: adin_file: failed to read speech data: "/home/pi/test.wav"エラー発生です。
どうやら、test.wavのチャンネル数が1chでない、即ち、ステレオのようです。
モノラルにしないと使えないようですので、変換ソフトがないか調べてみました。どうやら、soxというオープンソースを使えばできそうです。
参考資料は、これです。
Soxで音声形式を変換する(wav <–> aiff <–> au <–> wav)
soxのインストール
sox をインストールします。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ sudo aptitude install soxステレオ、モノラル変換してみました。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ sox /home/pi/test.wav -c 1 /home/pi/test_1.wav
sox WARN dither: dither clipped 4070 samples; decrease volume? ワーニングらしきものが出てきましたが、構わず進みます。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C main.jconf -C raw_am-gmm.jconf -nostripすると、以下のエラーが出てきました。
------
### read waveform input
Error: adin_file: sampling rate != 16000 (44100)
Error: adin_file: error in parsing wav header at (null)
Error: adin_stdin: failed to read speech data from stdin
reached end of input on stdin どうやら、サンプルレートが正しくないようです。16,000Hzでないといけないと言っているようです。
そこで、soxで、サンプルレートも与えてみます。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ sox /home/pi/test.wav -c 1 -r 16000 /home/pi/test_1.wav再実行
再実行したところ、今度はうまく流れたようです。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C main.jconf -C raw_am-gmm.jconf -nostrip ### read waveform input
enter filename->/home/pi/test_1.wav
Stat: adin_file: input speechfile: /home/pi/test_1.wav
STAT: 82007 samples (5.13 sec.)
STAT: ### speech analysis (waveform -> MFCC)
### Recognition: 1st pass (LR beam)
...............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................pass1_best: 本 は 何 。
pass1_best_wordseq: <s> 本+名詞 は+助詞 何+代名詞 </s>
pass1_best_phonemeseq: silB | h o N | w a | n a N | silE
pass1_best_score: -11000.291992
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 59776 generated, 4078 pushed, 592 nodes popped in 511
sentence1: 本年 は 何 。
wseq1: <s> 本年+名詞 は+助詞 何+代名詞 </s>
phseq1: silB | h o N n e N | w a | n a N | silE
cmscore1: 0.266 0.010 0.422 0.034 1.000
score1: -11049.955078 うーん。結果は思わしくないですな!
60爺の声だと、滑舌が悪いせいか、正しく認識してくれませんね。
音声サンプルによる認識
60爺の声では、きちんと認識しないので、サンプル音声を探してきて、やってみることにしました。
サンプル音声ダウンロード
サンプル音声は、ここからいただきました。
サンプル音声/無料ダウンロード
ダウンロードします。ここにあるのは、MP3形式のサンプル音声ですね。
pi@raspberrypi:~ $ wget https://www.voice-pro.jp/announce/mp3/ohayo01kawamoto.mp3 --2017-09-29 08:21:34-- https://www.voice-pro.jp/announce/mp3/ohayo01kawamoto.mp3
www.voice-pro.jp (www.voice-pro.jp) をDNSに問いあわせています... 210.172.183.41
www.voice-pro.jp (www.voice-pro.jp)|210.172.183.41|:80 に接続しています... 接続 しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 47518 (46K) `ohayo01kawamoto.mp3' に保存中 ohayo01kawamoto.mp3 100%[=====================>] 46.40K --.-KB/s 時間 0.04s 2017-09-29 08:21:35 (1.09 MB/s) - `ohayo01kawamoto.mp3' へ保存完了 [47518/47518] pi@raspberrypi:~ $ ls
Desktop Templates julius-4.3.1.tar.gz sqlite3
Documents Videos julius-4.4.2.tar.gz test.txt
Downloads dictation-kit-v4.3.1-linux.tgz julius-kits test.wav
Music grammar-kit-v4.1.tar.gz ohayo01kawamoto.mp3 test_1.wav
Pictures graph_data_db.sqlite oldconffiles
Public julius python_games
Raspi julius-4.3.1 python_pg Juliusはモノラルwav形式でなければ認識できないので、wav形式に変換をかけねばなりません。
sox変換でエラー発生及び対応
ところが、soxで変換をかけようとしたら、以下のようなエラーとなります。
pi@raspberrypi:~ $ sox /home/pi/ohayo01kawamoto.mp3 -c 1 -r 16000 /home/pi/test_2.wav
sox FAIL formats: no handler for file extension `mp3' pi@raspberrypi:~ $ sox /home/pi/ohayo01kawamoto.mp3 /home/pi/test_2.wav channel
s 1 rate 16k
sox FAIL formats: no handler for file extension `mp3'soxってmp3の変換はかけられないのかって思い、別ソフトを探してみたのですが、意外と面倒くさそうです。
そこで、少し調べてみると、下記ページには、soxで、ちゃんと変換できますって載ってますね。
今更聞けない目的別soxの使い方
でもって、もう少し調べてみたら、こんなことが書いてあります。60爺は、linuxの素人ですから、へェーってなとこです。
ubuntuでは、sudo apt-get install libsox-fmt-mp3でよいようですが、fedoraではlibsox-fmt-mp3はないのでだめみたいです
ラズパイではどうかな?
libsox-fmt-mp3を試しにinstallしてみたら、無事、インストールできました。
pi@raspberrypi:~ $ sudo aptitude install libsox-fmt-mp3
以下の新規パッケージがインストールされます:
libsox-fmt-mp3 libtwolame0{a}
更新: 0 個、新規インストール: 2 個、削除: 0 個、保留: 0 個。そこで、mp3 ⇒ wav変換をかけたところ、うまくいきました。
さー、テストが出来ます。
サンプル音声による音声認識
pi@raspberrypi:~ $ sox /home/pi/ohayo01kawamoto.mp3 /home/pi/test_2.wav channels 1 rate 16kやってみました。
pi@raspberrypi:~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C main.jconf -C raw_am-gmm.jconf -nostrip ### read waveform input
enter filename->/home/pi/test_2.wav
Stat: adin_file: input speechfile: /home/pi/test_2.wav
STAT: 47229 samples (2.95 sec.)
STAT: ### speech analysis (waveform -> MFCC)
### Recognition: 1st pass (LR beam)
.....................................................................................................................................................................................................................................................................................................pass1_best: 母 いや 。
pass1_best_wordseq: <s> 母+名詞 いや+感動詞 </s>
pass1_best_phonemeseq: silB | h a h a | i y a | silE
pass1_best_score: -5929.034180
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 57654 generated, 2598 pushed, 322 nodes popped in 293
sentence1: アン ハイヤー は 。
wseq1: <s> アン+名詞 ハイヤー+名詞 は+助詞 </s>
phseq1: silB | a N | h a i y a: | w a | silE
cmscore1: 0.739 0.031 0.042 0.035 1.000
score1: -5950.773926 うーん、こちらの結果も余り芳しくありませんでした。
いろいろなページを見ると、皆さん、あっさりうまく良くと書いてありますが、素人の60爺では、辞書ファイルをそのまま使ってもうまくいかないようです。
師匠に聞くと、どうやら、辞書をきちんと作らんとダメみたいですね。
part3では、辞書作りに挑戦します。
※Julius音声認識のシリーズ記事です。他の記事もご覧になってください。
- Julius音声認識ソフト番外編!音声でロボット操作準備で障害続出
- Julius音声認識ソフトpart4!音声によるロボット操作の準備作業
- 一般ユーザで音声出力できても管理者IDで実行すると音が出ない理由とは
- Julius音声認識ソフトpart3!フリーでも文法ファイルで認識率アップ
- Julius 音声認識ソフト part1 フリーソフトだがセッティングでエラーの嵐!
最後に
part1でセッティングを行ったJuliusで音声認識を継続しました。
マイクからの音声入力を行った前回に続き、今回は、録音したファイルを入力にして音声認識を行いました。
Juliusへの入力は設定ファイルにある、-input mic を、-input rawfile に変えればいいだけでした。
音声ファイルをダウンロードし、音声変換を行って音声認識を実行しましたが、辞書ファイルに改善の余地がありそうです。
■思えば、「Julius音声認識」の記事も増えてきました


60爺
60路を越え、RaspberryPi と出会い、その関係でブログ開設(2017/2~)となりました。始めてみると、コツコツやるのが性に合ってしまい、漢字の記事から家の補修・将棋・windows10関係・別名・言い方などジャンルを拡大して今に至ってます。まだまだ、元気なので新たな話題を見つけて皆様に提供できればと思っています。「プロフィールはこちら」